

この記事を読むと、
「ImportHTML() を使って ”特定のWebページの情報” を自動取得する方法」がわかります。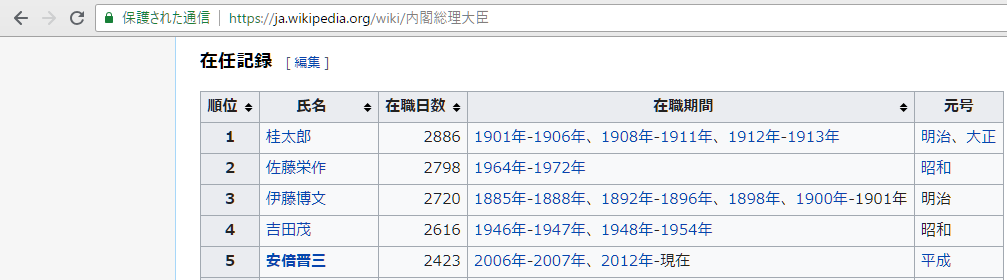
Wikipedia: 内閣総理大臣 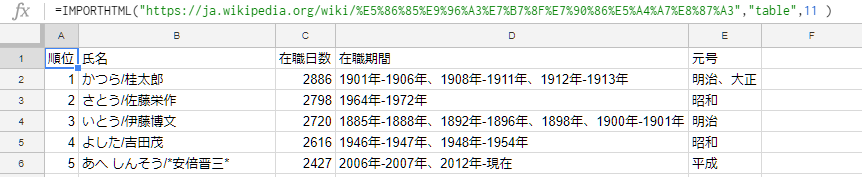
「ImportHTML() を使って ”特定のWebページの情報” を自動取得する方法」がわかります。
=ImportHTML() で何ができる?
たとえば、Wikipediaの内閣総理大臣のページの情報を、
Googleスプレッドシートに自動取得することができます。
使う関数はひとつだけ。
難しい操作はまったくありません。
=ImportHTML() を使う手順
まずは、関数の内容を確認してみましょう。
=IMPORTHTML(URL, クエリ, 指数)URLは、取得したい情報が掲載されているWebページのURLです。
クエリには、「table」か「list」のいずれかが入ります。これは、どういう形の情報が掲載されているかを示していて、tableなら表、listはそのままでリスト形式のものを指しています。
指数では、上から順に何番目のtable(もしくはlist)なのかを番号で指定します。
上の例では、次のように指定しています。
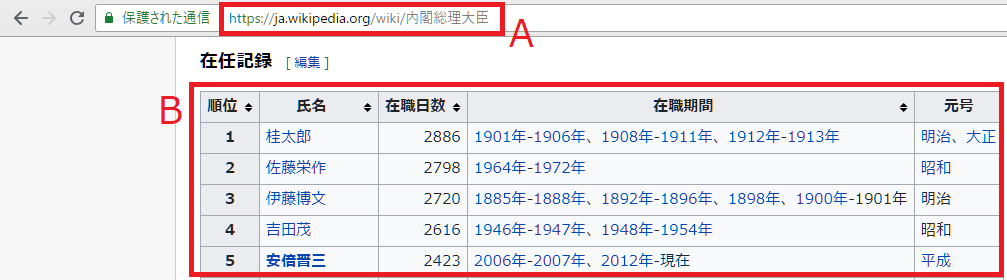
=IMPORTHTML("https://ja.wikipedia.org/wiki/%E5%86%85%E9%96%A3%E7%B7%8F%E7%90%86%E5%A4%A7%E8%87%A3","table",11 )Aが情報の掲載されているページのURL(コピペすると「https://ja.wikipedia.org/wiki/%E5%86%85%E9%96%A3%E7%B7%8F%E7%90%86%E5%A4%A7%E8%87%A3」となる)。
Bは、このページで11番目の表(table)なので、クエリは「table」に、指数は「11」を指定します。

タカハシ / 7年目の兼業トレーダー
このブログの目的は、「学習の備忘録」と「アウトプットして理解を深めること」。「トレードで稼ぐために学んだこと」を徹底的に公開していきます。
元・日本料理の板前、現・金融畑のウェブ屋さん
保有資格:証券外務員1種、認定テクニカルアナリスト
更新のお知らせは、各SNS や LINE@ で。LINE@ だと1対1でお話することもできます!
>> このブログと著者についての詳細
>> 使っているツールの紹介